반응형
Python(3.11.3)
웹 크롤링
Visual Studio Code
기초문법
자료형
- 튜플 : 초기화한 요소들을 수정 불가
requests 모듈
requests 모듈을 이용하여 요청하고, 페이지 정보를 가져오기
URL='https://hankyung.com'
response=requests.get(URL)
print(response.text)
print(response.status_code)URL 및 파라미터 사용하여, 페이지 정보 가져오기
URL='https://search.naver.com/search.naver'
params = {"query":"finance"}
response=requests.get(URL,params=params)
print(response.status_code)
print(response.content)공공데이터 json으로 받아서 출력
requests 모듈을 이용하여 오픈 API에 요청 데이터를 받아서 사전식 자료형을 변환하여 사용
이때, 서비스키 값은 일반인증키의 Decoding을 사용하면 오류 해결가능
url = 'http://apis.data.go.kr/1160100/service/GetStocDiviInfoService/getDiviInfo'
params ={'serviceKey' : '', 'pageNo' : '1', 'numOfRows' : '1', 'resultType' : 'json', 'crno' : '1101110057012', 'stckIssuCmpyNm' : '동남합성' }
response = requests.get(url)
print(response.status_code)
result=response.json()
print(result)
item=result['response']['body']['items']['item'][0]
print(item['stckIssuCmpyNm'])
print(item.items())
print("-----------------")
for key,val in item.items():
print("key:{} val:{}".format(key,val))
# 여러 종목들이 저장되어 있는 리스트
itemResults=result['response']['body']['items']['item']
print("-----------------")
for item in itemResults:
for key,val in item.items():
print("key:{} val:{}".format(key,val))
print("-----------------===============")인덱싱
txt="안녕하세요 웹 크롤링합니다."
print(txt[0])
print(txt[0:3])
print(txt.index('웹'))
print(txt[txt.find('웹'):txt.find('링')])
#공백지우기
txt2="<a>네이버웹툰이동하기 "
txt3="</a>"
print(txt2.strip()+txt3)
#문자바꾸기
txt4="<p>네이버</p>"
print(txt4.replace("p","div"))
안
안녕하
6
웹 크롤
<a>네이버웹툰이동하기</a>
<div>네이버</div>re
정규표현식
import re
# re.search(): 형식에 매칭되는 문자열 구함
# group(): 매칭된 문자열을 모두 반환
# sub(): 패턴에 맞는 문자열을 찾아 다른 값으로 대체
txt5="<div><p>ITCampus</p></div>"
p=re.search('<p.*/p>',txt5)
print(p)
p=p.group()
print(p)
p=re.sub('<.+?>','',p)
print(p)
<re.Match object; span=(5, 20), match='<p>ITCampus</p>'>
<p>ITCampus</p>
ITCampus네이버 인기종목 구하기
#종목구하기
print("=====종목구하기=====")
#tbody 범위 구하기
tbody= temp[temp.find("<tbody>"):temp.find("</tbody>")]
# print(tbody)
ths=tbody.split('<th scope="row">')
itemList=[]
for i in ths:
a=re.search('<a.*/a>',i)
if(a !=None):
a=a.group()
itemList.append(re.sub('<.+?>','',a))
for k in itemList:
print('종목 : {}'.format(k))
=====종목구하기=====
종목 : 유니온머티리..
종목 : 에코프로
종목 : 삼천리
종목 : 유니온
종목 : 에코프로비엠urllib모듈 활용
- urllib.request : urlopen()
해당 URL을 열고 응답 데이터는 바이트 형식의 HTTPRequest 객체 또는 URL을 직접넣는다 - urllib.request : read()
urlopend()으로 열어준 객체를 읽고, 인자로 전달하는 숫자만큼 데이터를 읽어준다 - urllib.request : decode()
바이트 형식의 데이터를 원하는 형식으로 변환(기본값으로 utf-8사용) - urllib.request : urlretrieve()
웹 이미지를 다운로드 하는 기능
#이미지 주소 복사
img_src='이미지주소'
new_name='C:/workspace_python_web_crawling/dog.png'
urllib.request.urlretrieve(img_src,new_name)- urllib.parse
네이버에서 연관검색어 목록 가져오기
import urllib
import urllib.request
import urllib.parse
import re
# query='파이썬'
query_list=['파이썬','자바','c언어','c++']
URL='https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=1&ie=utf8&query='
for i in query_list:
new_URL= URL+urllib.parse.quote(i)
response_urllib = urllib.request.urlopen(new_URL)
byte_data = response_urllib.read() #데이터 읽어오기
text_data = byte_data.decode() #디코딩하기
# print(text_data)
text_data=text_data.split('연관 검색어')[1].split('더보기')[0]
text_data=re.search('<div class="tit">.*/div>',text_data)
text_data=text_data.group() # 매칭값 가져오기
text_data=re.sub('<.+?>','',text_data)
# print(text_data)
text_data=text_data.replace(' ',' ')
print(text_data)
print('==========================================')beautifulSoup 모듈 활용
웹페이지 내 데이터를 쉽게 추출할 수 있도록 지원하는 라이브러리
- 태그를 사용하기 편한 파이썬 객체로 제공
네이버의 뉴스 목록가져오기
from bs4 import BeautifulSoup
import requests
request=requests.get("https://naver.com")
html=request.text
soup=BeautifulSoup(html,'html.parser')
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.div['id'])
print('====================')
result=soup.find_all('img', class_='news_logo')
newsListBeauti=[]
for i in result:
newsListBeauti.append(i.get('alt'))
print(newsListBeauti)
출력
<title>NAVER</title>
title
NAVER
u_skip
====================
['노컷뉴스', '한겨레', '스포츠조선', '뉴데일리', '오마이뉴스', '블로터', '스포탈코리아', '조선일
보', '한국경제TV', 'SBS', 'JTBC', '이데일리', '시사인', '파이낸셜뉴스', '지지통신', '여성신문', '르몽드 디플로마티크', '뉴스엔', 'YONHAPNEWS', '조세일보', '독서신문', '스포티비뉴스', '헬스조선', '스포츠Q']find, find_all
print(soup.find('img'))
print(soup.find(id='u_skip'))
#find_all(태그,속성) 검색
print(soup.find_all('a',class_='thumb'))
print(soup.find_all('a',attrs={'class':'thumb'}))select,select_one
#select,select_one로 검색
print(soup.select_one('a'))
print("------------------------")
print(soup.select('a'))네이버 스포츠 야구 순위,팀이름
import requests
from bs4 import BeautifulSoup
#네이버 스포츠 야구 순위 페이지
URL='https://sports.news.naver.com/kbaseball/record/index?category=kbo'
req=requests.get(URL)
html=req.text
soup=BeautifulSoup(html,'html.parser')
result=soup.select('.emblem+span')
ranking_list=soup.select('.emblem+span')
for i in range(len(ranking_list)):
print("{} 위 : {}".format(i+1,ranking_list[i].get_text().strip()))get_text,get('속성'),string
- get_text() : 결과값에서 태그를 제외한 텍스트
- get('속성') : 결과값에서 태그의 해당 속성의 값
- string : 결과값에서 태그 안에 또 다른 태그가 없는 경우만 출력
print(soup.find('title').get_text())
print(soup.find('div').get('id'))
print(soup.find('div',attrs={'id':'u_skip'}).string)데이터베이스 연동
- pip install mariadb로 설치
- import mariadb
#mariadb 연결
try:
conn=mariadb.connect(
user='root',
password='1234',
host='localhost',
port=3306,
database='hk'
)
except mariadb.Error as e:
print('Error MariaDB : {}'.format(e))
#insert문 실행기능(함수)
def insertInfo(rank,teamName):
cur =conn.cursor() # 쿼리 실행을 위한 객체 구함
cur.execute(f'INSERT INTO BASEBALL (RANK,TEAMNAME,REGDATE) VALUES ({rank},"{teamName}",SYSDATE())')
#crawling 데이터 DB에 insert하기
for i in range(len(ranking_list)):
insertInfo(i+1,ranking_list[i].get_text().strip())
conn.commit()
conn.close()조회기능
#조회를 위한 select문 실행 기능
def selectInfo():
cur=conn.cursor()
cur.execute('SELECT RANK, TEAMNAME FROM BASEBALL')
#Result-set 결과 출력하기
for (rank,teamname) in cur:
print(f"rank: {rank}, teamname: {teamname}")
selectInfo()
출력
rank: 1, teamname: 롯데
rank: 2, teamname: SSG
rank: 3, teamname: LG
rank: 4, teamname: KIA
rank: 5, teamname: 두산
rank: 6, teamname: 키움
rank: 7, teamname: NC
rank: 8, teamname: 삼성
rank: 9, teamname: KT
rank: 10, teamname: 한화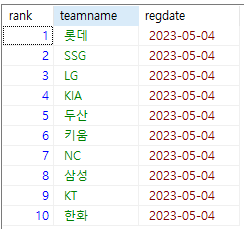
작업 스케줄러
window검색 - 작업스케줄러
- 파일로 미리만들어 놓은 insert문에 관련된 파일을 저장할 시간과 주기를 설정
- 정해진 시간에 알아서 파일이 실행되어 DB에 저장된 것을 볼 수 있음
Selenium모듈 활용
웹 어플리케이션 테스트를 위한 도구로 브라우저 동작의 자동화 지원
브라우저를 사용자가 아닌 프로그램이 제어
- pip install selenium설치
- https://chromedriver.chromium.org/download에서 설치 후 같은 경로
- from selenium import webdriver
- from selenium.webdriver.common.by import By
- 이벤트메서드를 이용하여 네이버 메인페이지에서 "사전"메뉴를 클릭하여 이동
- 영어사전,국어사전 이동
- 웹크롤링이라는 검색어 입력과 엔터키 처리
import selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.common.keys import Keys
path='C:/workspace_python_web_crawling/chromedriver_win32'
driver=webdriver.Chrome(path)
driver.get('https://naver.com')
element = driver.find_element(By.CLASS_NAME,'link_media')
print(element.text)
# 이벤트를 통해서 브라우저 제어 : click
dicElement = driver.find_element(By.CSS_SELECTOR,'.nav[href="https://dict.naver.com/"]')
dicElement.click()
dicElement=driver.find_element(By.ID,'_id_endic_href')
dicElement.click()
time.sleep(2)
dicElement=driver.find_element(By.ID,'_id_krdic_href')
dicElement.click()
time.sleep(2)
dicElement=driver.find_element(By.ID,'ac_input')
dicElement.send_keys('웹크롤링') #입력
dicElement.send_keys(Keys.ENTER)
time.sleep(2)네이버 로그인시 크롤링을 사용하면 자동입력 방지 문자 창으로 넘어감
결과적으로 Selenium과 BeautifulSoup을 적절히 사용하여 효율적인 결과를 출력하는 것이 필요
코딩테스트나 웹개발 시에 자주사용하는 문법, 습관같은 것을 기록하여 참고하는 프로그램을 만들어봐도 좋을 것 같음
검색 후 제목,내용 크롤링
import selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.common.keys import Keys
from bs4 import BeautifulSoup
path='C:/workspace_python_web_crawling/chromedriver_win32'
driver=webdriver.Chrome(path)
driver.get('https://naver.com')
# 이벤트를 통해서 브라우저 제어 : click
dicElement = driver.find_element(By.CSS_SELECTOR,'.nav[href="https://dict.naver.com/"]')
dicElement.click()
# dicElement=driver.find_element(By.ID,'_id_endic_href')
# dicElement.click()
# time.sleep(2)
dicElement=driver.find_element(By.ID,'_id_krdic_href')
dicElement.click()
dicElement=driver.find_element(By.ID,'ac_input')
dicElement.send_keys('웹크롤링') #입력
dicElement.send_keys(Keys.ENTER)
time.sleep(1)
#driver로 부터 페이지 소스를 받아 beautifulsoup으로 변환
page_source=driver.page_source
soup=BeautifulSoup(page_source,"html.parser")
searchRow=soup.select('.component_keyword .row')
# print(searchRow[0].select('.origin .link .highlight')[0].get_text().strip())
for row in searchRow:
resultWord=row.select('.origin .link .highlight')[0].get_text().strip()
row.select_one('.mean .word_class').decompose() # 삭제하기
row.select_one('.mean .mark').decompose() # 삭제하기
print(resultWord+ " : "+row.select('.mean')[0].get_text().strip())기타참고
open API 이용시 적용하는 방법 공부 필요
선택자(Selector)
- 자식 선택자 (>)
- 인접 선택자(+)
- 하위 선택자(공백)
반응형
'back-end > 기타' 카테고리의 다른 글
| (MyBatis)MVC2패턴- 게시판 (0) | 2023.03.24 |
|---|